Multi-threading - Automating Book Availability Checks
I am looking for a way to speed up the GHA that checks for books in the local library’s webpage.
Let’s look at the different steps of the GHA:
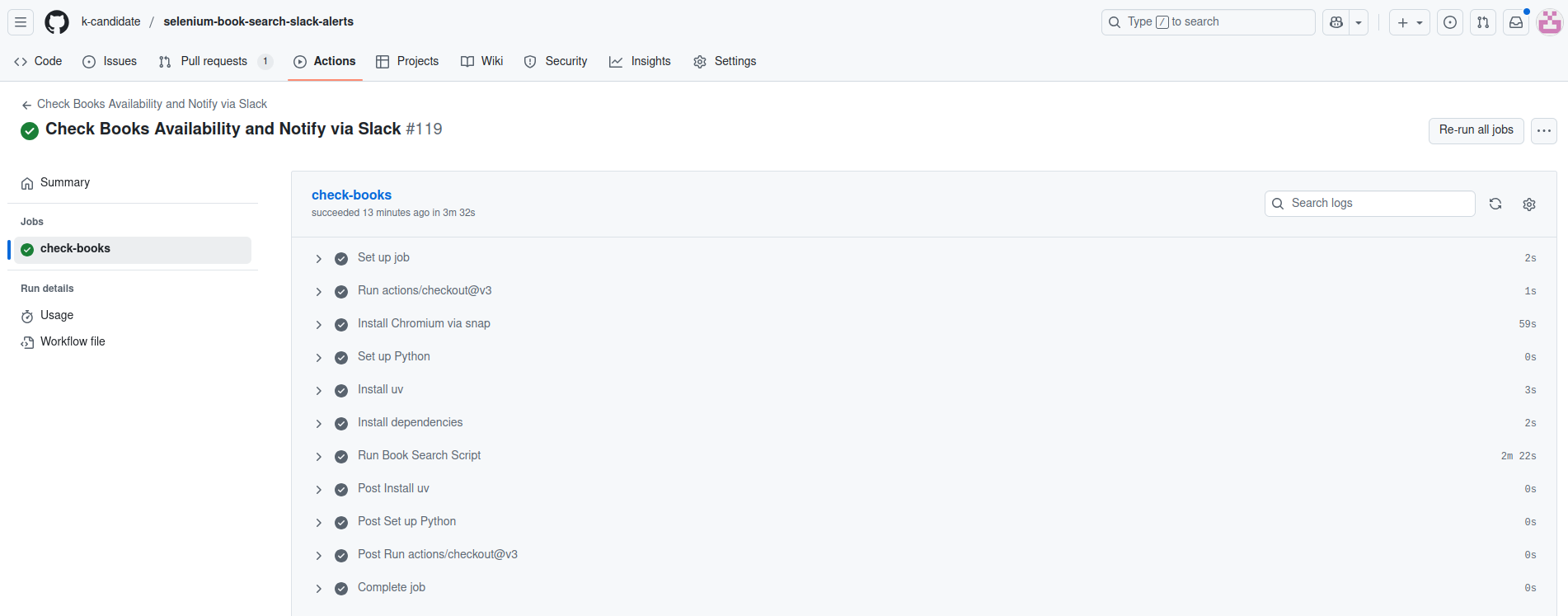
We can see that the step that takes the most time is the actual book search script itself.
In this case, we are not doing any heavy computations, and therefore we should not be CPU bound. Meaning that multiprocessing should not be necessary.
However, we are waiting for the server to respond to our requests, so we are I/O bound. Meaning we should benefit from multithreading.
Implementation
We could use the threading module. But I am going with the newer concurrent.futures which is a modern interface to threading (and also multiprocessing).
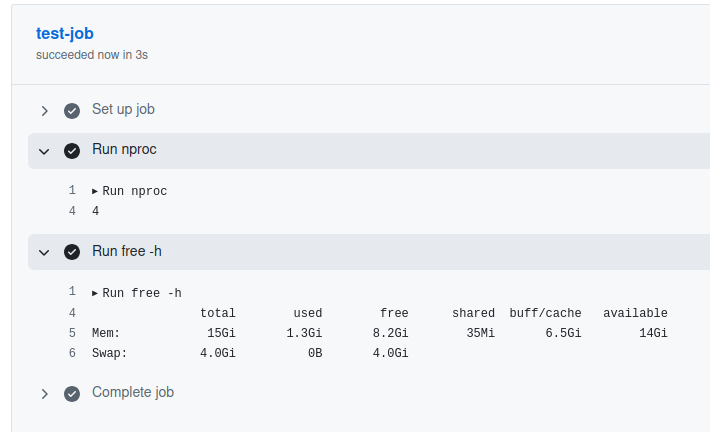
I wanted to know the resources I am working with in the public runner ubuntu-latest. It should handle 4 threads easily. See https://github.blog/news-insights/product-news/github-hosted-runners-double-the-power-for-open-source/. I verified that the information in that post matches reality:
You can find the change in this PR: https://github.com/k-candidate/selenium-book-search-slack-alerts/pull/10
Results
Here’s the same GHA with multi-threading:
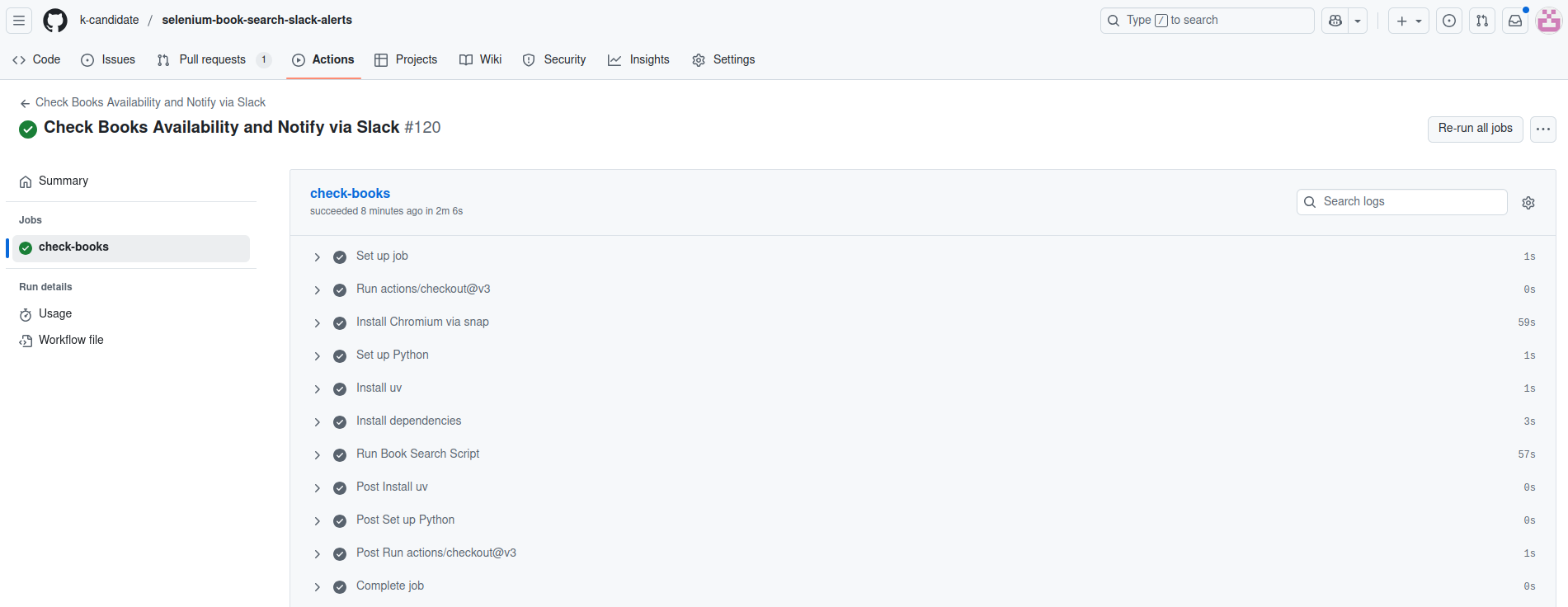
We went from 2m22s to 57s.
That’s a 60% reduction!